


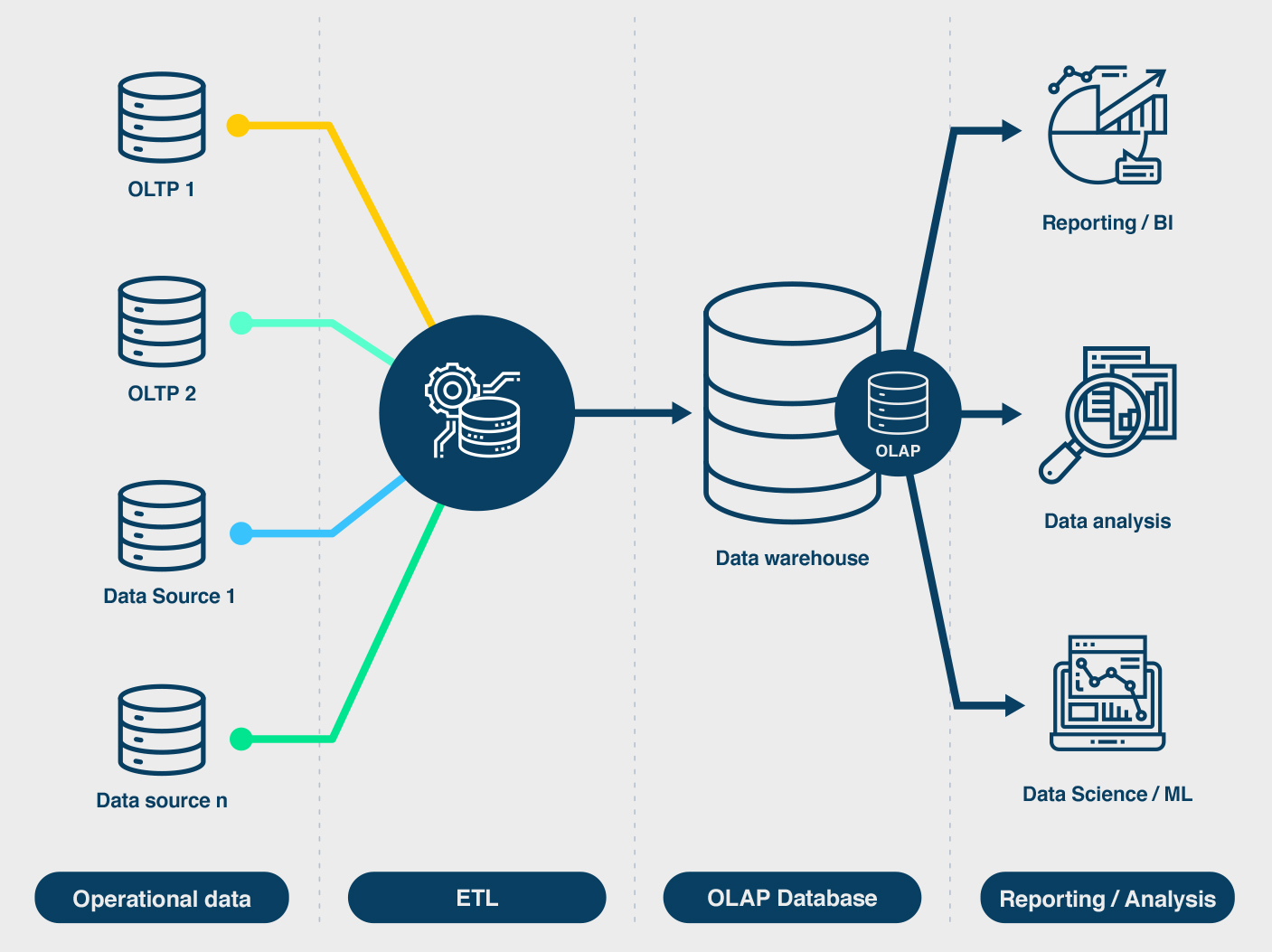

Fibre cheat sheet for commercial real estate professionals
Don’t know what you don’t know. Me too! Well at least that was the case before I tried writing this article. To save you time, here I condense and share my learnings about fibre. Hope you find this efficient summary of info enlightening and helpful.

