

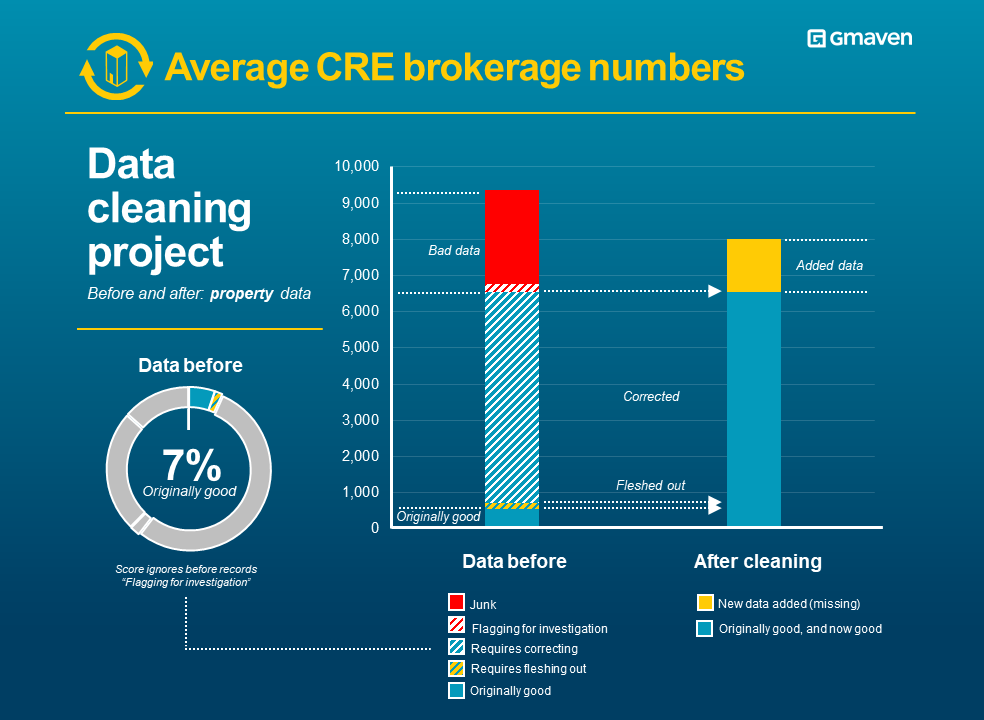
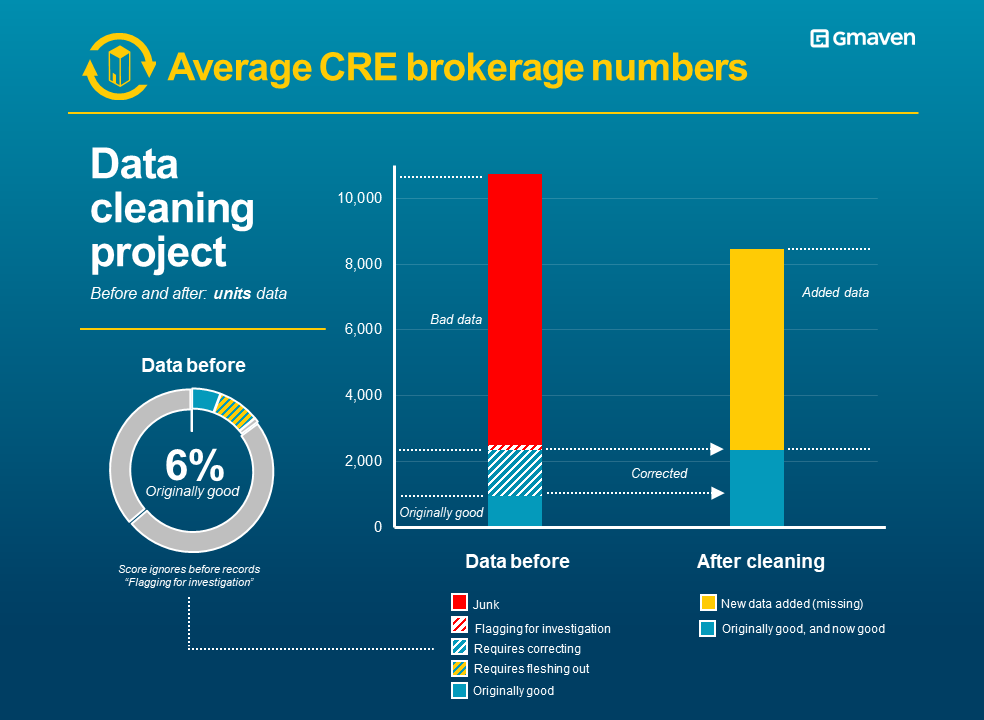
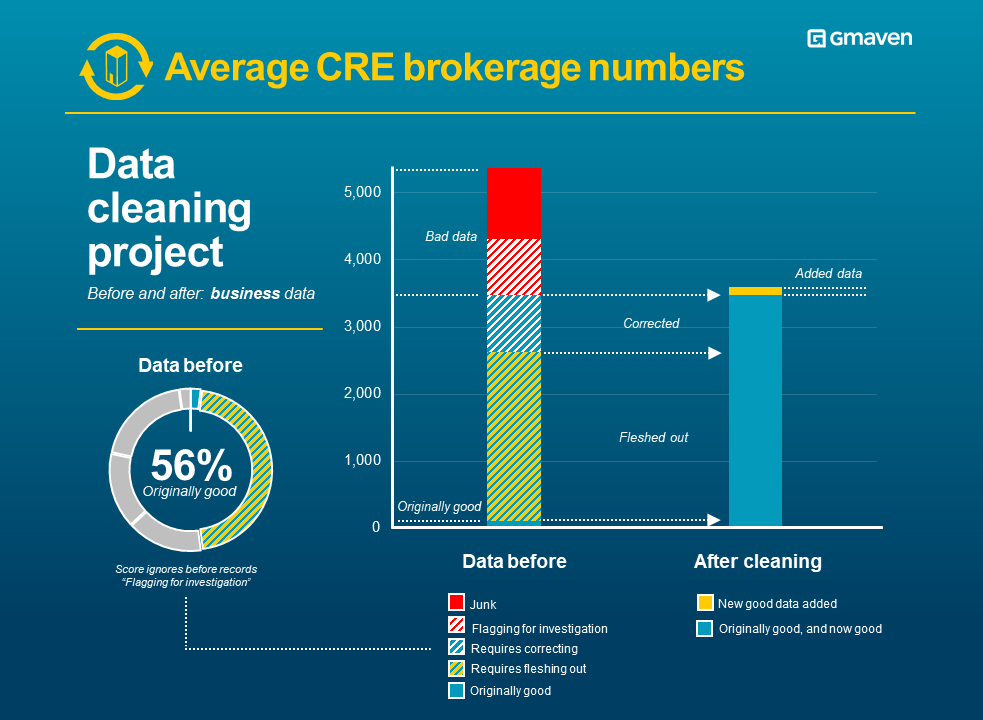
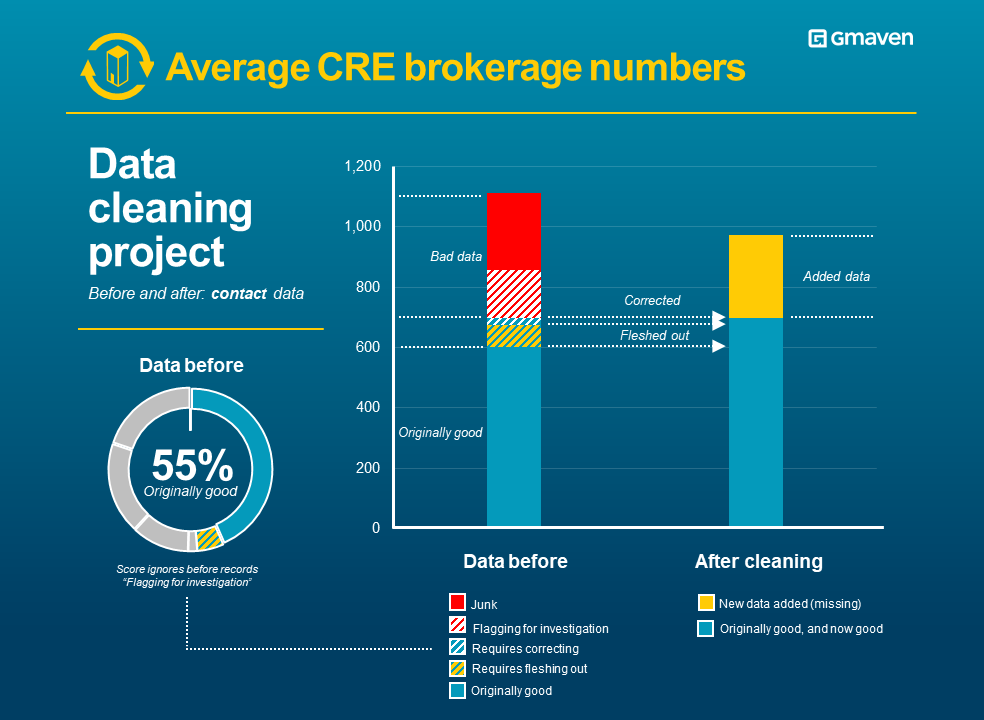

New: CRE vacancy schedules – best in breed
In a long-overdue industry first, PropTech is now delivering professionally-designed, automated vacancy schedules to the CRE industry. You time-starved CRE professionals can now get your vacancy schedules to work as hard as you do, giving your vacant space the best chance of finding the right tenant.

